
30. Least-squares Fitting to Data¶
Version of April 19, 2021
References:
Chapter 4 Least Squares of Sauer, Sections 1 and 2.
Section 8.1 Discrete Least Squares Approximation of Burden&Faires.
We have seen that when trying to fit a curve to a large collection of data points, fitting a single polynomial to all of them can be a bad approach. This is even more so if the data itself is inaccurate, due for example to measurement error.
Thus an important approach is to find a function of some simple form that is close to the given points but not necesarily fitting them exactly: given \(N\) points
we seek a function \(f(x)\) so that the errors at each point,
are “small” overall, in some sense.
Two important choices for the function \(f(x)\) are
(a) polynomials of low degree, and
(b) periodic sinusidal functions;
we will start with the simplest case of fitting a straight line.
30.1. Measuring “goodness of fit”: several options¶
The first decision to be made is how to measure the overall error in the fit, since the error is now a vector of values \(e = \{e_i\}\), not a single number. Two approaches are widely used:
Min-Max: minimize the maximum of the absolute errors at each point, \(\displaystyle \|e\|_{max} \text{ or } \|e\|_\infty, = \max_{1 \leq i \leq n} |e_i|\)
Least Squares: Minimize the sum of the squares of the errors, \(\displaystyle \sum_1^n e_i^2\)
30.2. What doesn’t work¶
Another seemingly natural approach is:
Minimize the sum of the absolute errors, \(\displaystyle \|e\|_1 = \sum_1^n |e_i|\)
but this often fails completely. In the following example, all three lines minimize this measure of error, along with infinitely many others: any line that passes below half of the points and above the other half.
import numpy as np
import matplotlib.pyplot as plt
from numpy.random import random
xdata = [1., 2., 3., 4.]
ydata = [0., 3., 2., 5.]
plt.figure(figsize=[12,6])
plt.plot(xdata, ydata, 'b*', label="Data")
xplot = np.linspace(0.,5.)
ylow = xplot -0.5
yhigh = xplot + 0.5
yflat = 2.5*np.ones_like(xplot)
plt.plot(xplot, ylow, label="low")
plt.plot(xplot, yhigh, label="high")
plt.plot(xplot, yflat, label="flat")
plt.legend(loc="best")
plt.show()
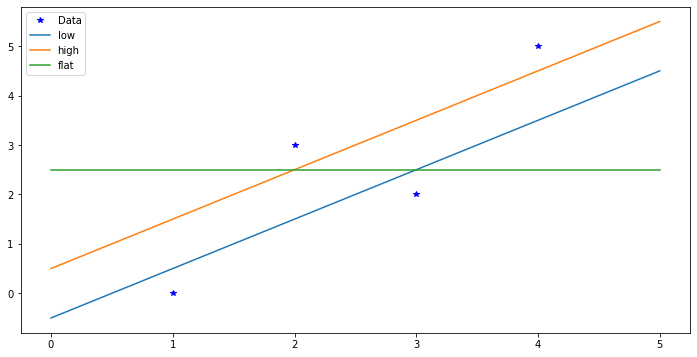
The Min-Max method is important and useful, but computationally difficult. One hint is the presence of absolute values in the formula, which get in the way of using calculus to get equations for the minimum.
Thus the easiest and most common approach is Least Squares, or equivalently, minimizing the root-mean-square error, which is just the Euclidean length \(\|e\|_2\) of the error vector \(e\). That “geometrical” interpretation of the goal can be useful. So we start with that.
30.3. Linear least squares¶
The simplest approach is to seek the straight line \(y = f(x) = c_0 + c_1x\) that minimizes the total square sum error,
Note well that the unknowns here are just the two values \(c_0\) and \(c_1\), and \(E\) is s fairly simple polynomial function of them. The minimum error must occur at a critical point of this function, where both partial derivatives are zero:
These are just simultaneous linear equations, which is the secret of why the least squares approach is so much easier than any alternative. The equations are:
where of course \(\sum_i 1\) is just \(N\).
It will help later to introduce the notation
so that the equations are
with
(Python indexing wins this time.)
30.4. Geometrical derivation, with the normal matrix¶
There is another way to derive this result using geometry and linear algebra instead of calculus, via the normal matrix. If a project is done on this topic, that could be added to the discussion.
30.5. Python implementation: polyfit and polyval¶
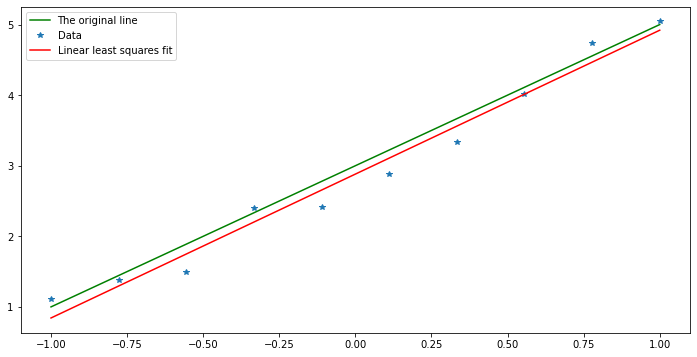
We now start to learn why the function polyfit(x, y, n) has that third argument, specifying the degree of the polynomial: it can be used to request a polynomial of degee one, and then it gives this least squares fit:
N = 10
x = np.linspace(-1, 1, N)
# Emulate a straight line with measurement errors:
# random(N) gives N values uniformly distributed in the range [0,1],
# and so with mean 0.5.
# Thus subtracting 1/2 simulates more symmetric "errors", of mean zero.
y_line = 2*x + 3
y = y_line + (random(N)-0.5)
plt.figure(figsize=[12,6])
plt.plot(x, y_line, 'g', label="The original line")
plt.plot(x, y, '*', label="Data")
c = np.polyfit(x, y, 1)
print("The coefficients are", c)
xplot = np.linspace(-1, 1, 100)
plt.plot(xplot, np.polyval(c, xplot), 'r', label="Linear least squares fit")
plt.legend(loc="best")
plt.show()
The coefficients are [2.03847991 2.88140609]
30.6. Least squares fiting to higher degree polynomials¶
The method above extends to finding a polynomial
that gives the best least squares fit to data
in that the coefficients \(c_k\) given the minimum of
Note that when \(N=n+1\), the solution is the interpolating polynomial, with error zero.
The necessary conditions for a minimum are that all \(n+1\) partial derivatives of \(E\) are zero:
This gives
or with the notation \(m_k = \sum_i x_i^k\), \(p_k = \sum_i x_i^k y_i\) introduced above,
That is, the equations are again \(Mc = p\), but now with
You might now be able to guess what other values of n do in polyfit(x, y, n),
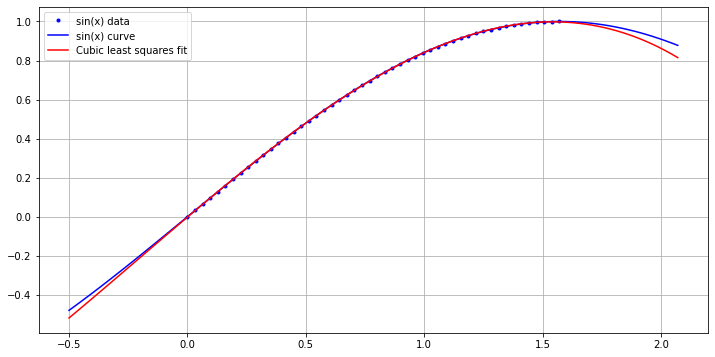
and we can experiment with a cubic fit to \(\sin(x)\) on \([0, \pi/2]\).
This time, let us look at extrapolation too: values beyond the interval containing the data.
N = 10
n = 3
xdata = np.linspace(0, np.pi/2, N)
ydata = np.sin(xdata)
plt.figure(figsize=[12,6])
plt.plot(xdata, ydata, 'b*', label="sin(x) data")
xplot = np.linspace(-0.5, np.pi/2 + 0.5, 100)
plt.plot(xplot, np.sin(xplot), 'b', label="sin(x) curve")
c = np.polyfit(xdata, ydata, n)
print("The coefficients are", c)
plt.plot(xplot, np.polyval(c, xplot), 'r', label="Cubic least squares fit")
plt.legend(loc="best")
The coefficients are [-0.11328717 -0.06859178 1.02381733 -0.00108728]
<matplotlib.legend.Legend at 0x7feb3d949df0>
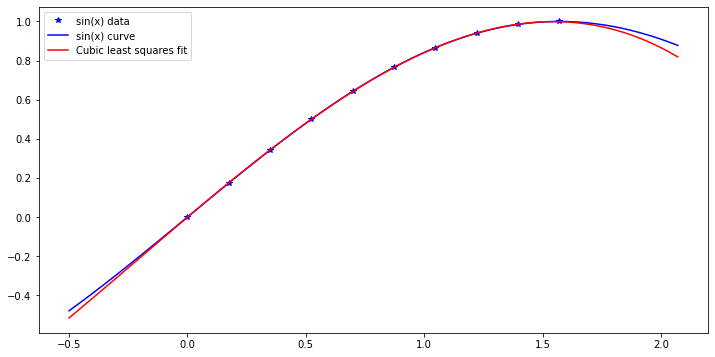
The discrepancy between the original function \(\sin(x)\) and this cubic is:
plt.figure(figsize=[12,6])
plt.plot(xplot, np.sin(xplot) - np.polyval(c, xplot))
plt.title("errors fitting at N = 10 points")
plt.grid(True)
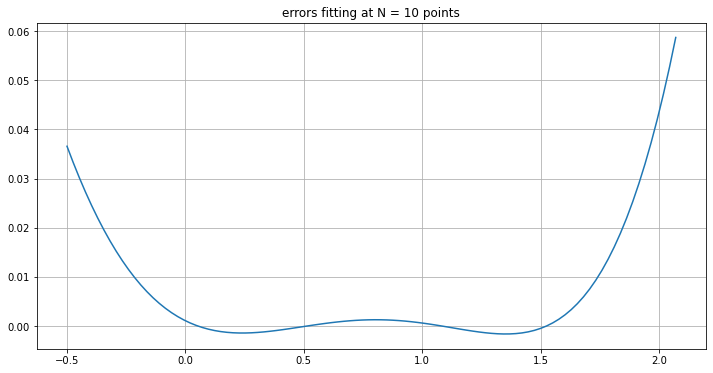
What if we fit at more points?
Not much changes!
This hints at another use of least squres fitting: fitting a simpler curve (like a cubic) to a function (like \(\sin(x)\)), rather than to discrete data.
N = 50
xdata = np.linspace(0, np.pi/2, N)
ydata = np.sin(xdata)
plt.figure(figsize=[12,6])
plt.plot(xdata, ydata, 'b.', label="sin(x) data")
plt.plot(xplot, np.sin(xplot), 'b', label="sin(x) curve")
c = np.polyfit(xdata, ydata, n)
print("The coefficients are", c)
plt.plot(xplot, np.polyval(c, xplot), 'r', label="Cubic least squares fit")
plt.legend(loc="best")
plt.grid(True)
The coefficients are [-0.1137182 -0.06970463 1.02647568 -0.00200789]
plt.figure(figsize=[12,6])
plt.plot(xplot, np.sin(xplot) - np.polyval(c, xplot))
plt.title("errors fitting at N = 50 points")
plt.grid(True)
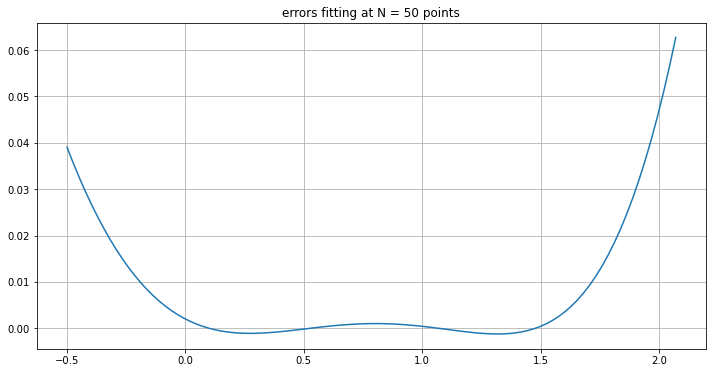
Not much changes!
This hints at another use of least squares fitting: fitting a simpler curve (like a cubic) to a function (like \(\sin(x)\)), rather than to discrete data.
30.7. Nonlinear fitting: power-law relationships¶
When data \((x_i, y_i)\) is inherently positive, it is often natural to seek an approximate power law relationship
That is, one seeks the power \(p\) and scale factor \(c\) that minimizes error in some sense.
When the magnitudes and the data \(y_i\) vary greatly, it is often appropriate to look at the relative errors
and this can be shown to be very close to looking at the absolute errors of the logarithms
Introducing the new variables \(X_i = \ln(x_i)\), \(Y_i = \ln(Y_i)\) and \(C = \ln(c)\), this becomes the familiar problem of finding a linear approxation of the data \(Y_i\) by \(C + p X_i\).
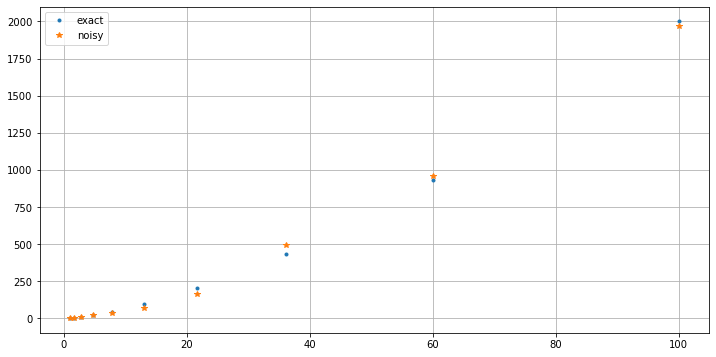
30.8. A simulation¶
#help(np.logspace)
c_exact = 2.
p_exact = 1.5
x = np.logspace(0.01, 2, 10)
xPlot = np.logspace(0.01, 2) # For graphs later
#print(x)
y_exact = c_exact * x**p_exact
y = y_exact * (1. + (random(len(y_exact))- 0.5)/2)
plt.figure(figsize=[12,6])
plt.plot(x, y_exact, '.', label='exact')
plt.plot(x, y, '*', label='noisy')
plt.legend()
plt.grid(True)
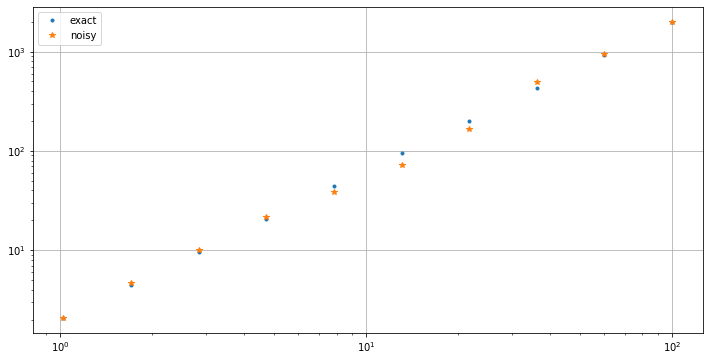
plt.figure(figsize=[12,6])
plt.loglog(x, y_exact, '.', label='exact')
plt.loglog(x, y, '*', label='noisy')
plt.legend()
plt.grid(True)
X = np.log(x)
Y = np.log(y)
pC = np.polyfit(X, Y, 1)
p = pC[0]
c = np.exp(pC[1])
print(p, c)
1.489726810407078 1.989934182730082
plt.figure(figsize=[12,6])
plt.plot(x, y_exact, '.', label='exact')
plt.plot(x, y, '*', label='noisy')
plt.plot(xPlot, c * xPlot**p)
plt.legend()
plt.grid(True)
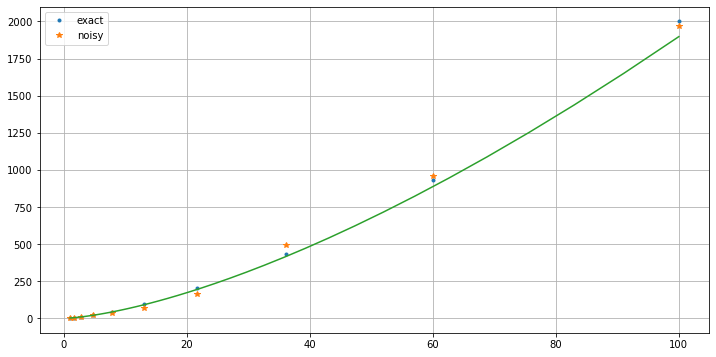
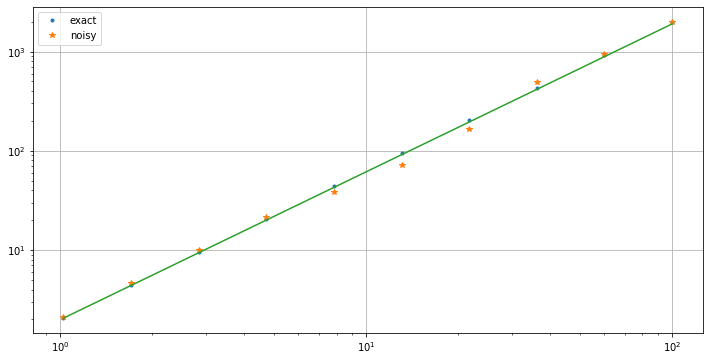
plt.figure(figsize=[12,6])
plt.loglog(x, y_exact, '.', label='exact')
plt.loglog(x, y, '*', label='noisy')
plt.loglog(xPlot, c * xPlot**p)
plt.legend()
plt.grid(True)
This work is licensed under Creative Commons Attribution-ShareAlike 4.0 International